
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
Anyone who sat through an EAI vendor presentation or has spent more than a few days on an integration project surely has come across the idea of a Hub-and-Spoke architecture. The basic idea of Hub-and-Spoke is pretty simple. It stems from the realization that a completely connected graph of n nodes requires n / 2 * (n -1) edges. If the graph is directed (more closely modeling typical integration systems with unidirectional channels) the number climbs to n * (n - 1). The scary part about this formula is the fact that the number of edges grows with the square of the number of nodes. For example, while 4 nodes require only 6 connections, 8 nodes already require 28 edges. The picture often associated with the dilemma looks like this:
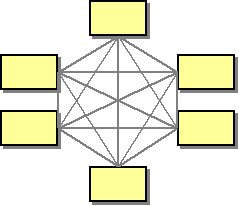
The general idea is that we can avoid the combinatorial explosion of the number of edges if we can replace the "web" with something that resembles a wheel with a central hub and spokes going out to all the nodes. In such a topology, the number of edges is equal to the number of nodes, which means it grows linearly.
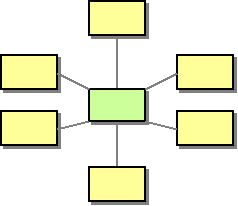
The airlines (and FedEx) have been implementing this idea for quite some time. It is much too expensive to fly airplanes directly from everywhere from anywhere. Instead, each carrier maintains a small number of central hubs and tries to route as many flights as possible through these hubs.
So far, so good. Hub-and-Spoke seems to be a great idea, so what else is there to say about it? When translating the concept of hub and spoke to the world of integration it is useful to have a closer look at what a connection between two systems really entails, i.e. what does the line between two boxes really represent? In some cases, the line might be a message queue, in other cases it might be a publish-subscribe topic or in yet other cases it might be the URI. So depending on the system, having a lot of lines might now immediately a problem. While it sure would be a pain to setup a lot of message queues, publish-subscribe topics and URI's are largely logical concepts and having a lot of them night mean a bit more maintenance but is unlikely to be the end of the world.
But the Hub-and-Spoke architecture also provides another significant benefit -- it decouples sender and receiver by inserting an active mediator in the middle - the hub. For example, this hub can perform the important function of routing incoming messages to the correct destination. As such, it decouples the sender of the message from having to know the location of the receiver. Having all messages travel though a central component is also great for logging messages or to control message flow. The Hub-and-Spoke style applied in this manner is commonly referred to as Message Broker because the hub brokers messages between the participants.
A Message Broker should also include a protocol translation and data transformation function. For example, a message may arrive via a message queue, but has to be passed on via HTTP. Also, location transparency is only an illusion unless data format translation is also provided. Otherwise, a change in the destination (i.e. a request in form of a message is now being serviced by another component) is very likely to require a change in the message data format. Without a Message Translator in between, the message originator would also have to be changed. Therefore, the implementation of this type of Hub-and-Spoke architecture typically includes data format translation capabilities.
The issue of data format translation raises a new point. Let's consider a scenario where each participant uses a different data format. If the Message Broker has to be able to forward any message to any other participant (possibly depending on a set of conditions), the broker now has to be able to convert between any data format and any other data format. While we solved the n-square problem at the physical level by inserting a central hub it seems that we are now facing the same problem at the data format level because creating a Message Translator between all possible combinations of n participants requires n / 2 * (n -1) translators. This notion is illustrated by the following diagram where every green dot indicates a required message format translation.
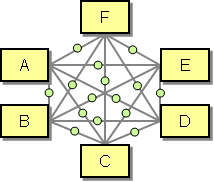
What gives? Are we always going to be haunted by the n-square problem? Not necessarily. We can apply the same hub-and-spoke concept to the issue of message formats, that is at the metadata level (metadata is the data that describes the format of messages). By introducing a "metadata hub" we can reduce the problem from n-square to a linear problem the same way as with the n-square physical connections. But what does a "metadata hub" look like? This time it is not a physical component, but a Canonical Domain Model that is common between all participants. When a message flows from participant A to participant B, the message format is first translated from A into the canonical format, and then from the canonical format into format B. It is sufficient to have a translation between each participant format and the canonical format, i.e. n translations for n participants (or 2*n if our transformations are unidirectional). Sometimes this concept is called "Semantic Hub-and-Spoke" but I generally prefer Canonical Domain Model to avoid confusion.
Are there any downsides to using a Hub-and-Spoke architecture? As always, there is no free lunch, so we expect to see some trade-offs. First of all, inserting a hub into the lines communication can cause additional overhead. Each message now has to make two hops instead of one, with a potential routing decision in between. This is likely to increase the latency of a message flowing between participants, just like a layover at an airline "hub" is going to make for a much longer journey than a direct flight. The hub can also become a performance bottle neck since all messages have to travel though this hub. In some cases we can mitigate this risk my deploying multiple instances of the hub process. In this case the hub is centrally configured at design-time, but distributed at run-time.
Another challenge can be the complexity of the hub. We now have to create a single thing that can accommodate each and every participant and data format. This concern also applies to the Canonical Domain Model. We have to find a common data representation that suits every participant equally well -- an effort that is all too rarely blessed with success (this might be worthy of a separate rambling).
Is Hub-and-Spoke the answer to every integration scenario? As always, the answer has to be a resounding "it depends!" If we look back at the original pictures and the motivation, you notice that two (somewhat related) assumptions were baked into the picture:
In reality this is rarely the case. Typically, we can layer services into infrastructure services that have little external dependencies and layer other services on top of these services. The resulting picture looks much more like a tree than a fully connected graph. In those cases, a Message Broker may still play a useful role as a level of indirection (i.e. acting as a directory of available services), but the n-square problem steps into the background.
I just noticed that Russell Levine published an article on this very topic in the November issue of Business Integration Journal (formerly EAI Journal). I guess great minds do think alike :-)


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.