
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
Last time I claimed that users like events. This time I want to show how I fulfilled my personal desire for events off the Web. A large portion of my "spare time" is occupied with writing. The scariest moment in a book author's life is the day the book goes on the shelf. Martin calls this the "will they like my baby??" moment, even though he has had little to worry about (but having set his own bar so high, so I am sure he is still nervous). Because technical authors really don't make much money off the books (unless you wrote Harry Potter and the Aggregator Pattern), reader reviews are often the primary source of bragging rights and Amazon stars carry a cachet close to the coveted Michelin stars.
Long story short, I like to know what people think about my book and like to be notified when a new opinion surfaces. Since this is a not a new desire I have built various solutions to this problem over the years. Join me in my chronology of being alerted over the Internet.
First there was the Web. Well, not quite. First there was the World without the Web. Before the Internet came around, getting actual feedback on your book involved physical or inter personal activity, which are both equally daunting to most technical authors. You could try to hang out a book store (preferably a busy venue like a conference book store) and prompt people along the lines of "A good friend of mine wrote this. Don't you think it is great?" Ah, the good old days. Fun but not very efficient.
Amazon started selling books over the Internet in 1995. Soon they realized that just selling individual items is merely a Web-enabled version of a traditional store. So Amazon started to transform their site from a mere store to a community, providing customers with recommendations, rankings and user reviews. Nowadays, user contributed content is counted as one of the key requirements to deserve that cool "Web 2.0" label, so Amazon was definitely a trend setter.
I could visit my book's page on Amazon and look at the customer reviews, implementing the polling protocol I described last time, i.e. I'd go there periodically to see whether anything changed.
If I was looking for automation I could access the page programmatically and "screen scrape" the information off the HTML source. Experience shows that screen scraping is cumbersome and brittle because changes in the page layout tend to break the "integration". Nevertheless screen scraping HTML was and is popular (for example, my Infogate tool relied on screen scraping to send relevant information to my cell phone) and one could even posit that Web crawling and indexing is a fancy version of screen scraping.
In 2002 Amazon launched their Amazon Web services, allowing users to access Amazon's data programmatically. Amazon provides both a REST-inspired interface and a SOAP interface, making it easy to access the store's information from about any programming language (and easy to get into lengthy REST vs. SOAP debates). Apply for a developer token, form an HTTP request, parse the resulting XML, and you have built an integration across the Internet. Very neat.
Naturally Web services allow for much more robust integration than screen scraping because the data format is more stable and free of formatting elements. To move closer to my original goal of receiving an alert for new book reviews, I created a variety of programs, the latest incarnation of which is written in Python (statically typed languages are so 2003).
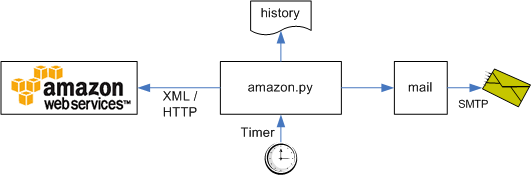
The program runs on a daily cycle (e.g., via a cron job) and performs the following steps:
A shell script sends the mail message using UNIX mail. The review history is stored in a simple text file. The whole setup works quite
well, but does require a bit of manual coding. I describe the program in more detail
below.
Hand-coding integration solutions is about as uncool as saying EAI in an SOA world. In preparation of next week's Mashup Camp I started to spend some time with various mashup tools, including Google Mashup Editor (see my GME tutorial on code.google.com) and Yahoo! Pipes. It occurred to me that combining these tools with my insights regarding events on the Web would make for a very elegant and simple solution:

Yahoo! Pipes can access an arbitrary XML data stream, manipulate it and re-publish it as an RSS feed, hosted by Yahoo. Using the widespread RSS format affords this solution a critical integration point that the previous solution was missing: I can use any RSS Feed reader to perform change tracking and alert me of new reviews, i.e. new items in the feed (see below). Or I could create another pipe that combines the RSS feed with data from another provider. This solution reduces the effort form some 100 lines of Python code to configuring a few elements in a drag-drop editor (see below for a detailed discussion of this implementation).
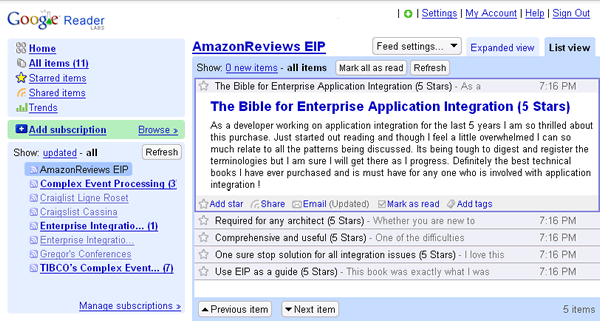
The solution is general enough to work with any ASIN, the Amazon Standard Identification Number used to reference items in Amazon's store.
What's next? Mashing up existing data into a feed is convenient but requires you to know the location and structure of the data source. If you imagine search technologies becoming more context aware and better at parsing structured information it might not be long until you can find any Web page that voices an opinion about my book. I occasionally do this by hand by searching for "Enterprise Integration Patterns" or doing a link search (search link:eaipatterns.com). However, the evaluation of the results is entirely manual and subjective. Maybe stronger search technologies will obsolete my Pipes-based solution within a year or two...
To prove that I am not in the "I used to be a coder" camp, here the actual solution in detail. Yahoo! Pipes follows a data flow model, represented as a pipeline of connected modules. Pipes provides a dozen or two predefined modules that provide for data retrieval, enrichment, and transformation. My Amazon Yahoo! Pipe looks as follows:
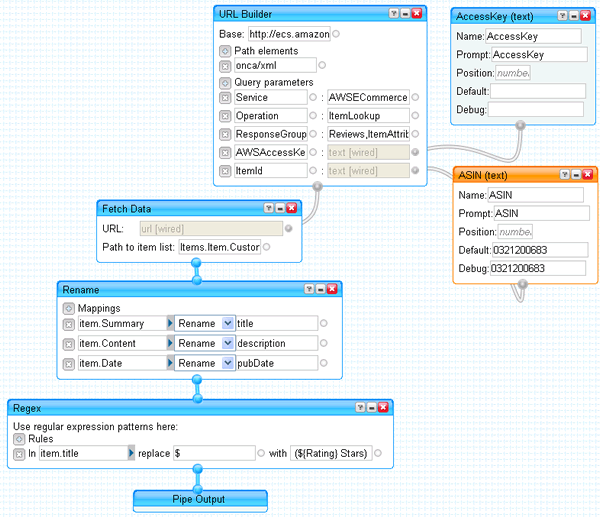
First, the pipe has to construct a URL to the Amazon Web service. The URL to the REST service is pretty straightforward and contains 2 parameters: the ASIN of the product to be retrieved and the Amazon developer token. The token is needed to perform throttling and enforce quota limits (you are allowed one request per second per IP). So while you are free to use my pipe I'll ask that you use your own developer token. You can get one at aws.amazon.com.
The final URL to access the Amazon Web service looks like this:
http://ecs.amazonaws.com/onca/xml?Service=AWSECommerceService&ResponseGroup=Reviews%2CItemAttributes&Operation=ItemLookup&ItemId=0321200683&AWSAccessKeyId=???
(replace ??? with your Amazon developer token).
The Fetch Data module hits this URL and extracts the specified node from the XML result. In our case the reviews are under Items.Item.CustomerReviews.Review (Pipes uses the dot notation as opposed to XPath). The Rename module copies the interesting fields for each review into the standard RSS elements (title and description). Lastly, we manipulate the title string field to also include the number of stars the reviewer awarded. The output is an RSS feed of reviews for the given ASIN:
<rss version="2.0" xmlns:geo="http://www.w3.org/2003/01/geo/wgs84_pos#"
xmlns:content="http://purl.org/rss/1.0/modules/content/"
xmlns:media="http://search.yahoo.com/mrss/">
<channel>
<title>AmazonReviews Gregor</title>
<description>Pipes Output</description>
<link>http://pipes.yahoo.com/pipes/pipe.info?_id=mmTwRpgw3BGOKomHyjUFzw</link>
<pubDate>Sat, 14 Jul 2007 00:53:32 PDT</pubDate>
<generator>http://pipes.yahoo.com/pipes/</generator>
<item>
<title>The Bible for Enterprise Application Integration (5 Stars)</title>
<description>As a developer working on application integration for...
</description>
<guid isPermaLink="false">...</guid>
</item>
<item>
<title>Required for any architect (5 Stars)</title>
<description>Whether you are new to integration architecture...
</description>
<guid isPermaLink="false">...</guid>
</item>
</channel>
</rss>
The exciting news is that a running Yahoo pipe is available from a public URL, allowing you to subscribe to the following URL from any RSS reader: http://pipes.yahoo.com/pipes/pipe.run?ASIN=0321200683&AccessKey=???&_id=lHe4hDAw3BGKdk3SdLq02Q&_render=rss&_run=1. Simply replace the AccessKey with your Amazon key, replace the ASIN with a product of your choice (e.g., the ISBN of a book) and you have an RSS feed for reviews!
If you like to see the pipe source or clone it for your experiments search for AmazonReviews on pipes.yahoo.com.
If you still live in the Web 1.5 world I am happy to share my Python program with you. The general flow is similar to the Yahoo Pipe, except the program has to do its own change tracking. The main method looks like this:
def main(args):
# process command line args
if len(args) > 1:
asin = args[1]
if asin == "help" or asin == "--help":
help(args[0])
sys.exit(0)
else:
asin = "0321200683"
if len(args) > 2:
tld = args[2]
else:
tld = "com"
print("Reviews for ISBN %s" % asin)
try:
dom = GetAmazonData("???", asin, tld)
except Exception:
print("Unable to connect to Amazon")
sys.exit(0)
print(getTitle(dom))
num = GetNumReviews(dom)
oldnum = ReadNumReviews(asin)
if (num != oldnum):
PrintReviews(dom)
WriteNumReviews(asin, num)
sys.exit(1)
else:
print("no new reviews")
sys.exit(0)
First, the program parses some command line arguments, such as the ASIN. By default it gets the reviews for my book. As with the Pipes implementation you need to provide an Amazon developer token, which you can request at aws.amazon.com. The method then forms the query URL and parses the results into an XML DOM. I use the built-in minidom library, which is somewhat limited but it allows this Python program to run without any external libraries. From the dom, the function gets the number of reviews and compares it to the last seen number of reviews (stored in a file). If there are new reviews, it writes the last 5 reviews (as reported in the XML document) to a file, which can be picked up by a shell script, for example to send an e-mail. The return value of the program indicates whether new reviews were found or not. Most of the code is straightforward enough. You can download the full source.
Let me point out the few gotcha's and surprises I hit:
getText() iterates over all text sub-nodes of a given node and concatenates them.
/tmp folder so if your OS does not have this path, you have to either create it or change
the method FileName()That's it. Download the source, install Python, and have fun!


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.