
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
It's hard to imagine an asynchronous system without queues aka Message Channels. Queues are the core element that provides location and temporal decoupling between sender and receiver. But there is quite a bit more behind the little barrel icons: control flow, traffic shaping, back pressure, and dead letters.
When Bobby and I wrote Enterprise Integration Patterns, we naturally spent most of the time on the data flow of messaging systems: how messages are generated, transformed, and routed. Some patterns, especially Endpoint Patterns such as Polling Consumer or Event-Driven Consumer clearly have a ring of control flow to it, but we never actually mention the term in the entire book (funnily there is one occurrence in Recipient List, but it's actually a verb and object: "In order for the Recipient List to control flow of information"). The term gets a few mentions in the blog, although we conclude that "Message-oriented API's steer towards a data flow architecture". So, it's time to make control flow a first-class citizen.
Like so many terms, Control Flow is also an overloaded term. In most imperative programming languages, control flow
relates to branching and loop statements. That control flow also exists in distributed
systems, where multiple entities execute local control flows. For example, a recipient
may be in a loop waiting for data whereas a sender may send a message whenever a user
clicks a button. Those control flows assume linearity, meaning one thing happens after
another: an if statement determines which branch will be executed, but it's only one or the other
(let's ignore speculative execution at the CPU level).
When designing asynchronous systems, we are interested in how these local control flows relate to each other. For example, when the user pushes a button and the sender sends a message, where does that message stay until the receiver's loop gets around to asking for a message? So, we are looking at the coordination across these local entities that determines the flow of messages:
In distributed systems, control flow indicates which element actively drives the interaction, for example by sending a message or calling a function.
Claude describes the differences between data flow and control flow as the "the what vs. the how": data describes what is being exchanged (and perhaps transformed along the way) whereas control describes how it gets there. A paper by old friend Schahram Dustdar makes the case for emphasizing data flow, ending up with a visual notation where "control flow decisions are encapsulated within the brick implementations", similar to Enterprise Integration Patterns (I forgive Schahram for not citing our book as he already cites Cesare, Olaf, Marlon, and James Lewis).
Control flow defines operational characteristics of a distributed system like scalability, robustness, or latency.
Although making the control flow implicit (as the above paper suggests) provides clean modeling and evocative diagrams, the run-time characteristics of such systems like scalability, robustness, or latency very much depend on control flow. So, when we build serverless IoT systems, for example, it behooves architects to make control flow a first-class consideration.
I often introduce distributed system ideas by starting with "2 boxes and a line". What starts so simple, turns out to be quite a bit more interesting once we zoom into the details. That casually drawn line could mean multiple things. Most diagrams show the flow of data from sender to receiver (almost all EIP diagrams do this without explicitly stating it). But the line could also indicate control flow, for example an RPC call. The following diagram illustrates common combinations of data and control flow:

Things get interesting with polling: the control flow is from right to left as the receiver actively calls the sender to fetch data.
Data and control flow may well point in opposite directions. When drawing an arrow, you should specify which flow it indicates.
The picture above is actually somewhat simplified for Messaging, as it doesn't account for Polling Consumers or Event-Driven Consumers. Once you place a queue in between sender and received (as most messaging systems do), the control flow becomes yet more interesting:

The sender can push messages at its preferred rate into the queue, meaning the control flow runs from the sender to the queue. Likewise, most queues support (or require) Polling Consumers, meaning the receiver's control flow points from right to left. Thus, we can express the magical property of queues by means of control flow:
A queue inverts control flow.
The absence of control flow from Enterprise Integration Patterns didn't escape some very smart people. Back in 2015 I wrote a blog post titled Sync or Swim, which was inspired by the work from old Google colleague, Ivan Gewirtz. Ivan worked in media processing, meaning high volume data processing pipelines. As compute capacities back then weren't what they are today, throughput and efficiency were important considerations. That's why his designs had to consider control flow along with data flow. Being a fan of the integration pattern icons, he realized that they don't express this aspect of system design:
Enterprise Integration Patterns only shows one half of distributed system design: the data flow.
Fortunately, it's relatively easy to extend the pattern icons to also show control flow by adjusting their shape. If each interaction can be actively pushing or polling data, or passively waiting to be called, we end up with four variations.

Although pushing and pulling are complementary to each other, they aren't the only control flow styles. Many cloud tools also support batch operations, adding cardinality in the mix (you could push or pull single elements or batches). Google Cloud additionally defines an Export Subscription for Pub/Sub in addition to push and pull. We'll come to these special cases later.
We can now combine the little noses and notches into four common combinations for elements in a Pipes and Filters architecture:

The element's role also determines what parameters a user has to specify to define the element's behavior. Pushers and Pullers typically don't take parameters related to control flow as they follow the control flow of the related Sender or Fetcher. Queues are passive, so they also don't take control flow parameters (they do take parameters related to flow control, such as retry counts or Time-to-Live / TTL; more on that in a subsequent post). A Driver is active, so it's usually configured via a polling interval (the maximum time between two subsequent message fetches) or batch sizes if batching is supported, as is the case in most high-throughput systems. Batching allows one fetch operation to retrieve multiple messages to reduce the polling overhead. However, large batches may exceed maximum payload sizes and cause inefficient error handling (if processing one message of the batch fails, either the entire batch or a subset have to be returned for retry). As we will soon see, the presence of such parameters often gives a hint at how cloud services are constructed.
The visual language of the little nooks and noses provides an affordance, an element that tells you how you can interact with an object. A toggle button on a light switch is an affordance, and much of Dan Norman's brilliant The Design Of Everyday Things discusses how poor affordances make us feel dumb, e.g. a door with a handle that screams "pull" combined with a small sign saying "push".
The Push and Pull affordances help us understand the control flow in asynchronous systems in an almost playful manner. If you want to connect a Sender to a Fetcher, you are faced with two noses pointing at each other. The only matching element to connect them is a Queue. Once connected, you can insert an arbitrary number of Pushers left of the Queue and Pullers to the right of it.

Likewise, it's easy to see that you need a Driver to connect a Source with a Sink. And once again, you can insert Pushers and Pullers al gusto.
Using the icons, finding the matching component and having a suitable name for it becomes so simple that we might feel it's not even worth discussing. In fact, that's exactly the point: finally, distributed system design feels as easy as assembling Lego bricks. Unsurprisingly, most cloud services include these concepts, but often without making them explicit.
Serverless integration services offered by cloud providers have to be scalable and robust, so it comes as no surprise that they are particular about push vs. pull control flow and batching of requests. Let's have a look at popular messaging services across the three major cloud providers.

Google Cloud leads the pack for supporting and clearly documenting Push and Pull subscriptions for their Pub/Sub service. And for each kind of access, they document how flow control is implemented:

GCP's Export subscriptions deliver data directly to another service like BigQuery or block storage, where the user does not have to specify a push or pull model.
Azure Event Grid also supports push and pull delivery.
AWS is less explicit about push or pull, implying the model based on type of service as opposed to giving you a choice. SQS (queue) uses a pull model as we would expect whereas SNS (Pub-Sub) uses a push model. EventBridge Buses also use a push model whereas EventBridge Pipes pulls messages and pushes them, acting as a Driver.
Cloud services that support push subscriptions aren't a direct pass through. Instead, the services buffer events (usually after filtering) before passing them to downstream services via active Drivers. The drivers work in parallel, arranged in worker pools, to achieve sufficient throughput (diagram on the left):
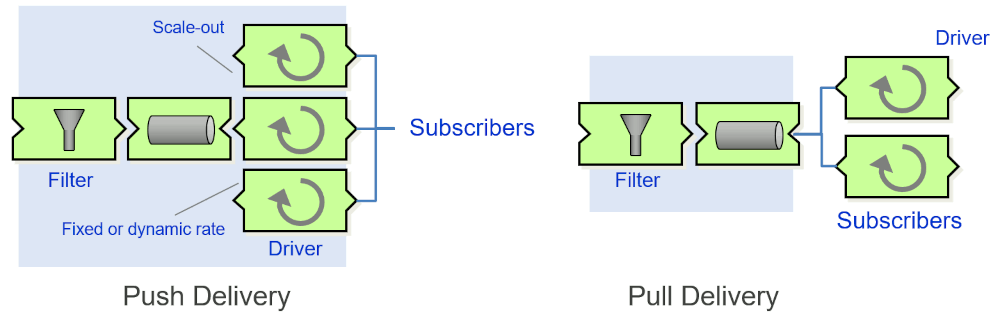
The parallel processing explains why these services don't maintain delivery order. All major providers make a disclaimer similar to Azure:
Event Grid doesn't guarantee order for event delivery, so subscribers may receive them out of order.
So, even services that look like a Pusher from the outside (because you feed messages in, and they in turn push messages out), have queues inside. Most documents don't state this explicitly, but once you read the documents (and have a good language to describe control flow), it becomes apparent.
These queues bring much needed stability, but also increase latency. Amazon EventBridge (which I happen to be most familiar with) reduced latency in 2023, but P90 latencies still hover around 250ms according to one heavy user. The docs even state "about half a second", which may render the service not a great fit for latency-sensitive operations. Also in 2023, Azure published (experimental) stats for Event Grid (which focus more on high throughput than latency) that results in an average latency of 11ms in Pull mode. It would be interesting to see P90/P95 values, as the graphs show some pronounced spikes. Overall, the service design is in line with the fundamentals of asynchronous system design:
Many serverless event routers optimize for high throughput and operational stability, not low latency.
Asynchronous, message-oriented services perform well under heavy load (more on that in a subsequent post) at the expense of latency. For a cloud provider, it's easy to see that the former trumps the latter as a design goal.
If you're looking to reduce latency, pull delivery can be the better option. Although polling is generally inefficient, both Azure and AWS users reported that pull delivery can yield lower latency than push, largely because the recipient controls the polling rate and batch size. The low latency may come at the expense of higher overhead (and perhaps hitting quota limits) when you use smaller batch sizes for polling, so it's worthwhile considering whether your application can live with the higher latency.
Some serverless event services get away without queues because they act as a Driver, meaning they have control over the rate at which they fetch messages. Amazon EventBridge Pipes fetches data from sources such as SQS queues or DynamoDB streams (as expected, the diagram on that page shows data flow, not control flow). If you look carefully at the supported sources (and you've read the AWS documentation carefully), you'll notice that all sources are Sources in our language, meaning they need an active Fetcher to retrieve data. This explains, why EventBridge Pipes cannot process events from SNS or S3 because they are active Senders. Two noses don't connect, however, you could connect them by inserting a Queue, as we saw above.

EventBridge Pipes having its own driver gives it some advantages. For one, it doesn't require a queue. Queues tend to be expensive and require flow control, as we will see in a future post. When Pipes sends message to a rate-limited target, it can simply slow down the fetch rate of its driver without having to buffer messages. The last advantage is likely the most desirable, in-order delivery:
If a source enforces order to the events sent to pipes, that order is maintained throughout the entire process to the target.
We quickly notice that the language could be more precise: The events aren't really sent, Pipes fetches them. Also, they don't need to be events but can be any form of message. Still, the result is laudable. As we saw, most event routers based on a queue and competing consumers do nor preserve order. Understanding the internal architecture of such services makes the design trade-offs apparent and easier to follow.
Assembling the icons with little noses and notches may seem playful, but also trivial in a way. I remember quite some time ago when I shared my messaging toolkit with a customer who for a course in integration patterns. When they looked at the icons and the simple domain language, their feedback was that this is beneath their audience. They somehow wanted things to feel more complicated.
The role of the pattern icons (for data flow and control flow) is to take the noise out and let you focus on the critical design decisions for your asynchronous systems. Once you do that, aspects like rate limiting or out-of-order delivery become apparent and no longer require you to read reams of documentation. That's the power of simple models:
If your decision seems trivial, you are using the right model.
Share: Tweet
Follow:
Follow @ghohpe
![]() SUBSCRIBE TO FEED
SUBSCRIBE TO FEED
More On: INTEGRATION CLOUD MESSAGING ALL RAMBLINGS


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.