
 Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Hi, I am Gregor Hohpe, co-author of the book Enterprise Integration Patterns. I work on and write about asynchronous messaging systems, distributed architectures, and all sorts of enterprise
computing and architecture topics.
Find my posts on IT strategy, enterprise architecture, and digital transformation at ArchitectElevator.com.
This is Part 3 of a mini-series on implementing the venerable EIP Loan Broker example With AWS Step Functions. Part 1 provides the tool and an overview of the basic design. It also implements the synchronous interface to the Credit Bureau. The previous implementation in Part 2 distributes quote requests to the banks via a Recipient List. In Part 3 we make this part more dynamic by using a Publish-Subscribe Channel and a stand-alone Aggregator, making up the Scatter-Gather pattern in combination. It's a slightly more complex implementation but it frees to Loan Broker from knowing how many banks there are or how they are implemented.
I almost forgot to mention that this is the 99th post in this blog, stretched over 18 years! That makes about one post every other month, reminding us how meaningless averages really are.
I often jest that Publish-Subscribe is one of the worst-named concepts because a) You subscribe before you publish (so the order is off) and b) You subscribe to a Message Channel but publish a Message (so it's mixing different concepts). I guess it just sound cute. I'll get off my tiny soap box and start implementing...
Having stated many times that architecture is about much more than product selection ("architects are the chef, not the person picking produce at the market"), let me contradict myself by doing a quick mapping of the constructs to AWS services. That way you can get a read which vicinity of the giant service tapestry we'll be dabbling in. Unsurprising we are mostly under "Application Integration":
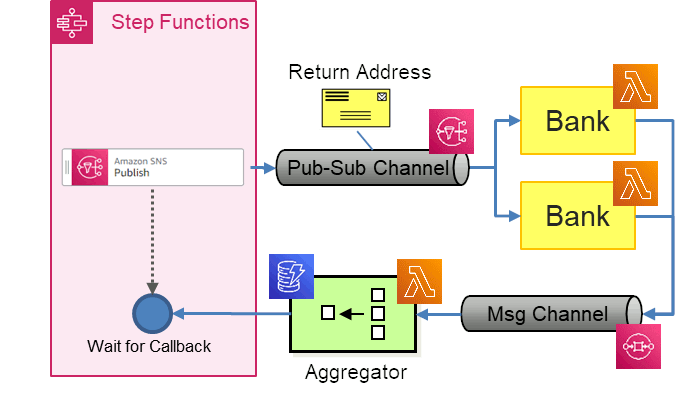
We'll use the following services to implement the Loan Broker:
You might wonder whether Amazon EventBridge might be a good fit here because it provides a serverless event bus. We'll get to that part later.
Just like before, I prefer diagrams that highlight a component's purpose ("semantics" if you prefer a bigger word) over the product choice, so the diagram shows the product logo as a decorator on the pattern icon. If you squint slightly, you can see that the SNS icon suggests multiple receivers whereas the SQS one has a single one. You might wonder why SQS sends messages in the form of a square whereas SNS seems to send funnels - that's because SNS includes Message Filters. The Step Functions logo is nicely expressive with the "Express" version even featuring cartoon-style slanted tasks!
With the product picks out of the way, let's get to what architects do best: make decisions.
What constitutes critical architecture decisions continues to be a hotly debated topic. Being a pragmatist, I have just two points of view on this:
Based on this conveniently fuzzy definition, I'd like to focus on two primary decisions that affect many distributed and especially event-driven systems.
The great benefit of loosely coupled systems is that they can be re-composed without requiring code changes or re-deployments. However, we not only learned that good composers are few and far in between, we can also decide whether we want our composition to be explicit or implicit (I was happily surprised that my post from 2005 also highlights design decisions):
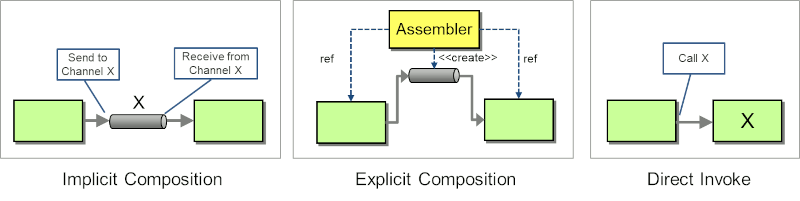
Composition can also take place by one component passing a Return Address to another component, freeing the receiving component from needing to configure the message channel for sent messages. However, the sending component needs to know the address to pass, either through implicit or explicit configuration or because it created the (usually temporary) channel. It's therefore similar to Direct Invocation, just in the reverse direction.
As described in a blog post on Correlation and Conversations from 2004 (apparently a productive year on my blog), messaging or event-based architectures differ substantially from call-stack-based applications. Because we're more used to call-stack based applications, developers often fall back into this model even when they're building event-driven applications. This also happened to the Loan Broker implementation in the book, as evidenced by the Visualization I subsequently generated, which looks awfully close to a call stack, as depicted on the left:

Event-driven applications, just like any message-oriented application, focus on the message flow and avoid request-response patterns. For our implementation, the key difference between the two approaches rests with the Aggregator. We might consider the Aggregator as part of the Loan Broker state machine that processes response messages, inching closer to a Request-Reply model. Another train of thought is to consider the Aggregator simply the next processing step after a Bank produced a quote, resembling a free flow of events.
The two decisions aren't completely independent. A call-stack-oriented architecture requires less composition. Essentially just the process manager needs to know channels for other components.
For this implementation we decide as follows:
Having satisfied our inner architect, it's time to crack open the Cloud Shell and start implementing. We will need to perform the following steps:
MortgageQuoteRequest.
MortgageQuotes, via Lambda and EventBridge.
You notice that we aren't building the system linearly, as many tutorials pretend it to be. Rather we are building around the banks, as that's the component we already have at hand and because it makes for meaningful tests along the way.
We implement the Publish-Subscribe Channel with Amazon SNS, the simple notification service. We create the channel from the command line and give our step function permission to publish to it, vie the role associated with it:
$ aws sns create-topic --name MortgageQuoteRequest
{
"TopicArn": "arn:aws:sns:us-east-2:1234567890:MortgageQuoteRequest"
}
$ aws sns add-permission --topic-arn=arn:aws:sns:us-east-2:1234567890:MortgageQuoteRequest \
--action-name=Publish --label=Mortgage \
--aws-account-id=arn:aws:iam::1234567890:role/service-role/StepFunctions-LoanBroker-role-abcdef
The bank implementation is almost the same as for our prior implementation with a recipient list, thanks to the ability to subscribe Lambda functions to an SNS topic via the API/CLI and being able to use Lambda Destinations to send response messages. The bank code looks as follows:
function calcRate(amount, term, score, history) {
if (amount <= process.env.MAX_LOAN_AMOUNT && score >= process.env.MIN_CREDIT_SCORE) {
return parseFloat(process.env.BASE_RATE) + Math.random() * ((1000 - score) / 100.0);
}
}
exports.handler = async (event, context) => {
console.log(event.Records[0].Sns);
const message = event.Records[0].Sns.Message;
const requestId = event.Records[0].Sns.MessageAttributes.RequestId.Value;
const bankId = process.env.BANK_ID;
const data = JSON.parse(message);
console.log('Loan Request over %d at credit score %d', data.Amount, data.Credit.Score);
const rate = calcRate(data.Amount, data.Term, data.Credit.Score, data.Credit.History);
if (rate) {
const quote = { "rate": rate, "bankId": bankId, "id": requestId};
console.log('Offering Loan', quote);
return quote;
} else {
console.log('Rejecting Loan');
}
};
This is one of my favorite parts of serverless deployment: our code is all but 20
lines with a minimal amount of noise (all code is available in the EIP Git Repository under LoanBroker/AwsStepFunctions/PubSub). As before, we parametrize the bank with the type of loan requests it publishes.
The bank loops through the request ID attribute, which acts as Correlation Identifier. You might be surprised that the function simply returns the quote as if it was invoked
synchronously. This is where a little but of Lambda magic will come into play. First
let's create bank instances based on this template. We ZIP up the JS file and create
three instances with respective parameters as before ($role is set to our Lambda role):
$ aws lambda create-function --function-name=BankSnsPawnshop \
--runtime=nodejs12.x --handler=BankSns.handler --role=$role \
--environment="Variables={BANK_ID=PawnShop,BASE_RATE=5,MAX_LOAN_AMOUNT=500000,MIN_CREDIT_SCORE=400}" \
--zip-file=fileb://BankSns.zip
$ aws lambda create-function --function-name=BankSnsUniversal \
--runtime=nodejs12.x --handler=BankSns.handler --role=$role \
--environment="Variables={BANK_ID=Universal,BASE_RATE=4,MAX_LOAN_AMOUNT=700000,MIN_CREDIT_SCORE=500}" \
--zip-file=fileb://BankSns.zip
$ aws lambda create-function --function-name=BankSnsPremium \
--runtime=nodejs12.x --handler=BankSns.handler --role=$role \
--environment="Variables={BANK_ID=Premium,BASE_RATE=3,MAX_LOAN_AMOUNT=900000,MIN_CREDIT_SCORE=600}" \
--zip-file=fileb://BankSns.zip
Now we need to subscribe the banks to the MortgageQuoteRequest SNS topic. Following our "no actions from the GUI" mantra, we do this from the CloudShell
command line (repeat for each bank):
$ aws sns subscribe --protocol=lambda \ --topic-arn=arn:aws:sns:us-east-2:1234567890:MortgageQuoteRequest \ --notification-endpoint=arn:aws:lambda:us-east-2:1234567890:function:BankSnsPawnshop
As you'd expect nothing happens if our friend IAM doesn't play along, so we need to give the banks permission to receive messages from the SNS topic. In the console this will be shown as a "Trigger" (thank you, Stack Overflow):
aws lambda add-permission --function-name BankSnsPawnshop \
--statement-id SnsInvokeLambda \
--action "lambda:InvokeFunction" \
--principal sns.amazonaws.com \
--source-arn arn:aws:sns:us-east-2:1234567890:MortgageQuoteRequest
You can now send a mortgage quote request message to the SNS topic and confirm the Banks being invoked with the CloudWatch logs (the SNS Console UI also has a nice Event Generator). This request has to include the data that the workflow will retrieve from the Credit Bureau:
$ aws sns publish --topic-arn arn:aws:sns:us-east-2:1234567890:MortgageQuoteRequest \
--message "{ \"SSN\": \"123-45-6666\", \"Amount\": 500000, \"Term\": 30, \"Credit\": { \"Score\": 803, \"History\": 22 } }" \
--message-attributes '{ "RequestId": { "DataType": "String", "StringValue": "ABC12345" } }'
What keeps tripping me up is that when sending the message the value has to be specified
in an element called StringValue, however, when the message is delivered, the field name is Value as you can see in the function's CloudWatch logs:
INFO {
Type: 'Notification',
TopicArn: 'arn:aws:sns:us-east-2:1234567890:MortgageQuoteRequest',
Subject: null,
Message: '{ "SSN": "123-45-6666", "Amount": 500000, "Term": 30, "Credit": { "Score": 803, "History": 22 } }',
MessageAttributes: { RequestId: { Type: 'String', Value: 'ABC12345' } }
[...]
}
Now that we can send mortgage quote requests to multiple banks, we need to build a mechanism for the banks to deliver their quotes to a single Aggregator. We'll do that via an SQS queue, which we setup with very basic parameters (we don't need to hang onto old responses, so we set a retention period of 5 minutes):
$ aws sqs create-queue --queue-name MortgageQuotes --attributes='{"MessageRetentionPeriod": "300"}'
{
"QueueUrl": "https://sqs.us-east-2.amazonaws.com/1234567890/MortgageQuotes"
}
Next, we allow all entities in the account to send and receive messages to this queue:
$ aws sqs add-permission --queue-url=https://sqs.us-east-2.amazonaws.com/1234567890/MortgageQuotes \ --aws-account-ids=1234567890 \ --actions SendMessage ReceiveMessage DeleteMessage ChangeMessageVisibility \ --label BanksSendQuotes
The Bank function code could publish to this queue, but I feel it's cleaner to let Lambda handle that without coding this dependency into the function. Lambda supports Destinations. Destinations allow you to chain asynchronous Lambda function invocations based on success or failure of the invocation, meaning you can send the results of one Lambda function to another function or (hear, hear!) an SQS queue. This is an elegant way to do a direct composition of our event chain, but it does come with a slight challenge: the SQS message will contain the whole event with a lot of extra detail that isn't relevant to the Aggregator. We hence use a EventBridge rule to filter all the extra stuff and then send the clean message to the SQS queue. As a side node, Destinations appear to have some limitations related to duplicate invocations and long wait times. Luckily neither affects us for this example.
With this insight, we will create an EventBridge rule and configure the Bank's Lambda function to send the function's results to this event bus. We'll handle the EventBridge config in the GUI (I know, I know - the challenge here is that getting the event pattern right is only really possible with an example event and a "test" button). EventBridge is managed via so-called "Event Buses" - you'd normally create one bus per application. We create a new "LoanBroker" event bus and ensure that all components are able to publish events to this bus by using one of the permission templates provided by the console UI:
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "PutForAll",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::1234567890:root"
},
"Action": "events:PutEvents",
"Resource": "arn:aws:events:us-east-2:1234567890:event-bus/LoanBroker"
}]
}
We now define a rule that accepts events from Lambda, strips unnecessary content, and publishes to SQS. This can be relatively easily done via the EventBridge UI. We define a custom event pattern to make sure we only handle loan quotes:
{
"detail": {
"requestContext": {
"functionArn": [{ "prefix": "arn:aws:lambda:us-east-2:1234567890:function:BankSns" }]
},
"responsePayload": {
"bankId": [{ "exists": true }]
}
}
}
Patterns match by example, so replicating the structure of the event that you are
expecting is enough, augmented by a few special expressions like exists. Our rule only processes events that originate from a bank function and have a bankId in the response (as always, you need to use your account ID).
EventBridge implements a Content Filter as part of the target settings. After selecting the SQS queue MortgageQuotes as the target, we configure the input to be a part of the event, in our case the
JsonPath expression $.detail.responsePayload. It can also be handy to specify a second target that logs the whole event message
to cloudwatch so that you can capture an event for testing. The setting looks like
this in the Console:

Armed with a functioning EventBridge event bus and rule (EventBridge has many more cool features like schema detection, btw), we now instruct Lambda to send an event to it whenever a Bank invocation succeeds.
$ aws lambda get-function-event-invoke-config --function-name=BankSns
$ aws lambda put-function-event-invoke-config --function-name=BankSnsPawnshop \
--destination-config='{ "OnSuccess": { "Destination": "arn:aws:events:us-east-2:1234567890:event-bus/LoanBroker" } }'
We're almost done - there's always IAM! Our Lambda role has to be given permission to push events to EventBridge:
aws events put-permission --event-bus-name=default --principal=1234567890 --action=events:PutEvents --statement-id=PutForAll
aws iam put-role-policy --role-name CreditBureau-role-abcdefg --policy-name AllowPutEvents --policy-document '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "events:PutEvents" ], "Resource": "*" } ] }'
We are now ready to send Mortgage Quote Requests to the SNS topic from our Step Functions workflow. Our setup so far looks as follows:

$ aws sns publish --topic-arn arn:aws:sns:us-east-2:1234567890:MortgageQuoteRequest \
--message '{ "SSN": "123-45-6666", "Amount": 500000, "Term": 30, "Credit": { "Score": 803, "History": 22 } }' \
--message-attributes '{ "RequestId": { "DataType": "String", "StringValue": "ABC123456789" } }'
You can easily poll the queue from the SQS console and will find that 3 banks responded with a loan quote:

The message format is nice and clean:
{
"rate": 5.1605995685644075,
"bankId": "PawnShop",
"id": "ABC123456789"
}
Instead of calling Lambda functions directly in a loop, our state machine only has to send a message to an SNS topic, making the flow very simple (aggregating results comes next):

The only challenging part is setting the message attribute. It appears that message attributes aren't supported in Workflow Studio yet, so we enter those in the state machine JSON directly. We use the state machine's execution ID as Correlation Identifier:
"SNS Publish": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"Message.$": "$",
"TopicArn": "arn:aws:sns:us-east-2:1234567890:MortgageQuoteRequest",
"MessageAttributes": {
"RequestId": {
"DataType": "String",
"StringValue.$": "$$.Execution.Id"
}
}
},
"End": true,
"ResultPath": "$.SNSResponse"
}
We can now invoke a workflow execution and observe loan quote messages arriving on the SQS queue from the console, just as we did when we sent the SNS message directly from the command line:
$ aws stepfunctions start-execution --name=mysnsrun \
--state-machine-arn=arn:aws:states:us-east-2:1234567890:stateMachine:LoanBroker-PubSub \
--input="{\"SSN\": \"123-45-6789\", \"Amount\": 500000, \"Term\": 30 }"
The messages arriving on the queue contain the execution ID composed of the workflow's
arn and the name we provided:
{
"rate": 4.592265542250188,
"bankId": "Universal",
"id": "arn:aws:states:us-east-2:1234567890:execution:LoanBroker-PubSub:mysnsrun"
}
The more complex part of Scatter-Gather is the message aggregation. There are two general approaches (yes, another design decision):
Option 1 only works if message channels and Aggregator instances are very lightweight. With a serverless environment like Lambda that's the case but it turns out that correlating responses is quite simple in our case and we can easily store many aggregates in DynamoDB. So we'll go with option 2, although our Aggregator Lambda function is ephemeral, meaning its lifespan is only as long as a single message invocation. The way we make this work is by keeping state in DynamoDB.
For a change we implement the new Lambda Function QuoteAggregator in Python:
import boto3
import json
import logging
import decimal
logger = logging.getLogger()
logger.setLevel(logging.INFO)
dynamo = boto3.resource('dynamodb')
def lambda_handler(event, context):
for record in event['Records']:
quote = json.loads(record['body'])
logger.info(quote)
table = dynamo.Table('MortgageQuotes')
record = table.get_item(Key={'Id': quote['id'] }, ConsistentRead=True)
item = record.get('Item', { 'Id': quote['id'], 'Quotes': [] } )
item['Quotes'].append( { 'bankId': quote['bankId'], 'rate':"%.2f" % quote['rate'] })
logger.info(item)
table.put_item(Item = item)
return 0
We clock in again at just about 20 lines! Alas, some of them require additional comments:
id field in an incoming quote message to check if any related quotes are present. If
not, it initializes an empty quote list under this id. In either case it appends the
received quote to the quote list and persists the result in the DynamoDB. This can
be achieved without conditionals as get_item returns an empty dict if no item is found in the database. The Python method get allows a default if the key isn't found in the dict. So, in any case, out item ends up with an Id and a (perhaps empty) Quotes list.
float data types. It does accept Decimal but that does with two problems: a) converting a float into a Decimal marks the Decimal as "inexact" and b) Python doesn't like to convert Decimals into JSON. So we store the rates as strings.
bankId and a rate. You just have to make sure to get all the [], {}, and '' right. I often open up
Python in interactive mode to get the data structures right.
By now you have learned that not much happens in the cloud without permission, so
we need to allow the QuoteAggregator to consume messages from the SQS queue and read/write (aka GetItem, PutItem) into the DynamoDB. We created a second Table, again with a On-Demand provisioning
model.
$ aws iam put-role-policy --role-name CreditBureau-role-abcdefg --policy-name AllowSqs --policy-document '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "sqs:*" ], "Resource": "arn:aws:sqs:*:1234567890:MortgageQuotes" } ] }'
$ aws iam put-role-policy --role-name CreditBureau-role-abcdefg \
--policy-name AllowDynamo \
--policy-document '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "dynamodb:GetItem", "dynamodb:PutItem"], "Resource": "arn:aws:dynamodb:*:1234567890:table/MortgageQuotes" } ] }'
Finally, we configure the QuoteAggregator function to receive messages (it's worth having a look at the Documentation):
$ aws lambda create-event-source-mapping \ --function-name QuoteAggregator --batch-size 5 \ --event-source-arn arn:aws:sqs:us-east-2:1234567890:MortgageQuotes
With the proper permissions in place, you can now kick off the LoanBroker workflow as before:
$ aws stepfunctions start-execution --name=snsrun --state-machine-arn=arn:aws:states:us-east-2:1234567890:stateMachine:LoanBroker-PubSub --input="{\"SSN\": \"123-45-6789\", \"Amount\": 500000, \"Term\": 30 }"
{
"executionArn": "arn:aws:states:us-east-2:1234567890:execution:LoanBroker-PubSub:snsrun",
"startDate": "2021-08-15T10:28:23.653000+00:00"
}
The DynamoDB table should contain the quotes it received from the banks, keyed by
the id that corresponds to the arn of the StepFunctions workflow execution:
$ aws dynamodb get-item --table-name=MortgageQuotes \
--key='{"Id": {"S": "arn:aws:states:us-east-2:1234567890:execution:LoanBroker-PubSub:snsrun"}}'
{
"Item": {
"Id": {
"S": "arn:aws:states:us-east-2:1234567890:execution:LoanBroker-PubSub:snsrun"
},
"Quotes": {
"L": [ { "M": { "rate": { "N": "6.61" }, "bankId": { "S": "PawnShop" } } },
{ "M": { "rate": { "N": "6.24" }, "bankId": { "S": "Universal" } } },
{ "M": { "rate": { "N": "4.34" }, "bankId": { "S": "Premium" } } }
]
}
}
}
The creative structure aside (L denotes a list, M a map, and so on), we now have collected and persisted mortgage quotes in a convenient
place.
There's one part missing: we need to pause the workflow until the Aggregator reaches a completeness condition or times out. We could have the LoanBroker workflow poll the DynamoDB table until a sufficient number of quotes arrives. However, that approach is not only inefficient, it also couples the workflow back to the Aggregator implementation. It'd be much nicer if the Aggregator can notify the workflow that the Aggegrate is complete. It turns out we can achieve that by using Task Tokens.
We achieve this by marking the SNS Publish task as Wait for callback and supplying the magic variable $$.Task.Token as the Id message attribute (this has to be done in the workflow code editor). We
then add the following code to the QuoteAggregator Lambda function:
from botocore.exceptions import ClientError
sfn = boto3.client('stepfunctions')
def complete(item):
return len(item['Quotes']) >= 2
def lambda_handler(event, context):
[...]
if complete(item):
logger.info('Aggregate complete')
try:
sfn.send_task_success(taskToken=item['Id'], output=json.dumps(item['Quotes']))
except ClientError as ce:
logger.info('Could not complete workflow %s' % item['Id'])
logger.info(ce)
So, sending an asynchronous task completion is actually quite simple! You just have
to remember to convert the Python dict back into JSON - send_task_success won't accept Python's string representation. We define the Aggregator's completeness
condition as having at least 2 quotes available. Recall that the Aggregator is unaware
of how many banks there are as well as that a bank isn't require to produce a quote.
For the Aggregation Function, we choose simple concatenation as before, meaning the
Loan Broker will see all quotes and the bank who provided it.
Naturally, we need to give the aggregator permission to send task success. Unlike many other policies, this one does not allow us to specify the resource, presumably as the token is resource-agnostic ("opaque"):
$ aws iam put-role-policy --role-name CreditBureau-role-abcdefg \
--policy-document '{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:SendTaskSuccess" ], "Resource": "*" } ] }'
--policy-name AllowSuccess \
If you inspect the Aggregator's logs, you'll find that quote messages received by
the Aggregator after the completeness condition is reached lead to a TaskTimeOut error because the workflow has already been completed on a prior message. We simply
ignore this error.
The workflow ends up with the following data set:
{
"SSN": "123-45-6789",
"Amount": 500000,
"Term": 30,
"Credit": {
"Score": 863,
"History": 4
},
"Quotes": [
{ "bankId": "Premium", "rate": "4.95" },
{ "bankId": "Universal", "rate": "5.98" }
]
}
We set a Task timeout on the SNS Publish task so our workflow doesn't get stuck if the Aggregator doesn't receive the required number of quotes. If this happens, though, we might have received quotes, although not sufficiently many to satisfy the Aggregator. At this point we might return the quotes that we have as opposed to returning empty-handed. Our Aggregator isn't aware of the timeout condition, so it isn't able to handle this case. The workflow should fetch the existing results from the DynamoDB, although that'd couple the workflow to the database format, which isn't desired. So, we'd wrap the database access in another Lambda to encapsulate the data format.
Alas, we are running into a more serious problem: the task token, referenced by $$.Task.Tokenisn't accessible from the error path, leaving us without a key into the MortgageQuotes table. I can imagine two solutions:
send_task_success.
The second option seems a bit too clever (aka kludgy), so I prefer option 1. We'll
start by replacing the expression to define the RequestId with the following expression that concatenates execution ID and Task Token (States.Format is a handy function that was added in August 2020:
"States.Format('{}::{}', $$.Execution.Id, $$.Task.Token)"
We don't need to modify the banks because they see the ID as an opaque value. We do
need to modify the Aggregator, though, to split the Id into the Execution Id (to be
used as database key) and the task Token (to be used when calling send_task_success (notice the shared knowledge, aka "coupling", of the id format consisting of the
execution id and the task token separated by "::"):
try:
(key, token) = quote['id'].split("::")
except ValueError:
logger.error("Invalid quote id %s" % quote['id'])
return 0
Python can assign arrays to tuples, throwing a ValueError if the array doesn't contain sufficiently many elements. In our case this would happen
if the Id field lacks the :: separator, in which case split simply returns the whole string as a single element.
Now we slightly adjust the rest of the function to use the variables key and token:
record = table.get_item(Key={'Id': key }, ConsistentRead=True)
item = record.get('Item', { 'Id': key, 'Quotes': [], 'Token': token } )
item['Quotes'].append( { 'bankId': quote['bankId'], 'rate': "%.2f" % quote['rate'] })
table.put_item(Item = item)
if complete(item):
logger.info('Aggregate complete: %s' % token)
try:
sfn.send_task_success(taskToken=token, output=json.dumps(item['Quotes']))
except ClientError as ce:
logger.info('Could not complete workflow %s' % item['Id'])
The last part we now need is a simple lambda function that returns any values stored in the database for a given key:
import boto3
import json
dynamo = boto3.resource('dynamodb')
def lambda_handler(event, context):
key = event['Id']
table = dynamo.Table('MortgageQuotes')
record = table.get_item(Key={'Id': key }, ConsistentRead=True)
if 'Item' in record:
return {'Quotes' : record['Item']['Quotes'] }
else:
return {'Quotes' : [] }
Configuring the workflow to call this function in case of a timeout is relatively simple with a timeout setting and a catcher. In the Amazon States Language that looks as follows:
"SNS Publish": {
[...]
"TimeoutSeconds": 5,
"Catch": [ {
"ErrorEquals": [ "States.Timeout" ],
"Next": "GetAggregate",
"ResultPath": "$.Error",
"Comment": "Timeout"
} ]
},
There's one slight snag, though with the data formats. Naturally, we want the final
result to have the same format whether we completed the SNS task and got the results
from the QuoteAggregator or whether we timed out and got the results from GetAggregate. Both Lambda functions return a list of quotes, however, the result processing of
the Lambda Invocation doesn't handle lists directly. Rather, it insists on wrapping
the list in another elements. Merging those results back into the execution document
requires another node (you cannot merge results under the root node), leaving us with
an unavoidable double nesting:
"output": {
[...]
"result": {
"Quotes": [
{ "rate": "4.45","bankId": "Universal" },
{ "rate": "4.00", "bankId": "Premium" }
]
}
We rectify this with a Pass that that can lift the Quotes up. The final workflow looks as follows (it belies a bit the complexity underneath):

If the Aggregator receives sufficiently many quotes, it completes the SNS:Publish
task via the Task Token and the workflow ends. If the Aggregator doesn't complete
the task, it times out and calls the Lambda Function GetAggregate to fetch whichever quotes were received up to that point.
Phew! Let's quickly recap:
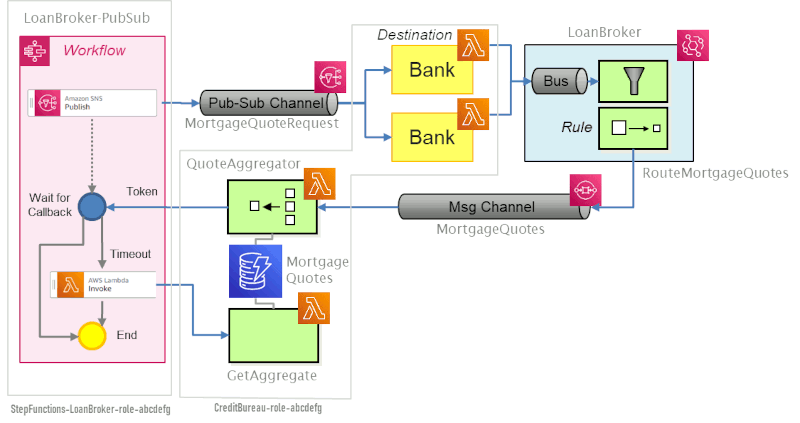
MortgageQuoteRequest. Any bank can subscribe to receive mortgage quote requests.
MortgageQuotes queue.
QuoteAggregator aggregates quotes and keeps state in DynamoDB. When a specified number of quotes
is received for one request, the aggregator notifies the workflow via task token.
Otherwise, the workflow task times out and retrieves the quotes that were received
so far from the DynamoDB via the Lambda function GetAggregate.
This being an example implementation and the blog post being already over 4000 words, we simplified some parts that would need further work if this were to be used in a real-life scenario:
MortgageQuotes DynamoDB table. We'd probably want to purge old aggregates periodically.
As commented at the end of Part 2, visualizing dependencies and communication paths in fine-grained distributed solutions is important, but not easy. The diagram above is an attempt at combining several solution layers without causing clutter:
Alas, there are many additional dependencies buried beneath. For example, the workflow
is configured to publish to a specific SNS topic. Likewise, the banks are subscribed
to this topic (implicit composition). The Lambda Destination is configured with the name of an EventBridge event bus
(direct invocation, although handled by the framework). Also, two Lambda functions share a database
and assume a specific data schema. On top of this, the workflow is aware of the data
format of the ID field used by the QuoteAggregator Lambda function.
Making these dependencies explicit will become easier (although not trivial) if we use automation (which is recommended in any case). Therefore, automation is about much more than just efficiency - it also serves an important documentation function. We'll dive into this in Part 4: Automation.


 Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.
Gregor is a cloud architect and author. He is a frequent speaker on asynchronous messaging,
IT strategy, and cloud.